
Professor Ard Louis is a theoretical physicist here at the Rudolf Peierls Centre for Theoretical Physics. His latest paper in Nature Communications identifies an inbuilt Occam’s razor that helps explain why the deep neural networks (DNNs) that power modern AI are so effective at learning from data.
Deep neural networks and Occam’s razor
Deep neural networks (DNNs) have revolutionised machine learning and artificial intelligence, and are increasingly transforming science, as recognised by this year’s Nobel prizes for Physics and Chemistry. However, their incredible success has puzzled experts for decades to the extent that they are often referred to as ‘black boxes’. This lack of understanding of how deep neural networks arrive at their conclusions has profound implications, making it difficult to explain or challenge decisions made by AI systems.
One key mystery is how they can predict so well on unseen data, even though they have millions or even billions more parameters than training data points. This goes against long standing intuitions in physics.
Consider this charming story told by the legendary theoretical physicist Freeman Dyson: He travelled to Chicago to show his new elementary particle physics calculations to Nobel Prize winner Enrico Fermi, proudly pointing out how closely they matched Fermi’s experimental data. However, upon learning that Dyson’s model relied on four free parameters, Fermi quipped: ‘I remember my friend Johnny von Neumann used to say, with four parameters I can fit an elephant, and with five I can make him wiggle his trunk.’ Fermi’s skepticism – that the agreement was merely an artifact of overfitting – was confirmed much later.
Stories like this are deeply embedded in the culture of physics. Indeed, early in their careers, undergraduates encounter lessons such as the one illustrated in Figure 1: Overly complex models, such as high-degree polynomial fits, fit training data well, but tend to perform poorly on new data. DNNs, however, ignore this cardinal rule. As shown in Figure 1, DNNs perform exceptionally well even with millions of parameters. This unexplained behaviour appears to ‘break basic rules of statistics’ in the words Yann LeCun, one of the founders of modern deep learning.
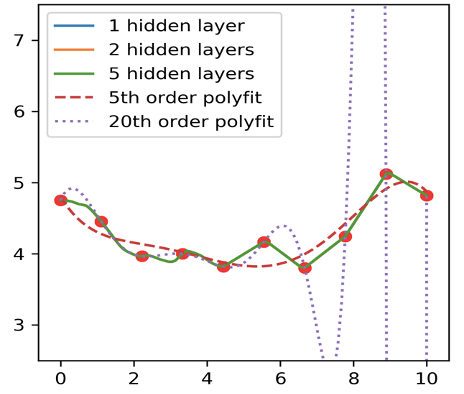
Since DNNs are complex models that can fit almost any conceivable function to the data they are trained on, they must have an inductive bias to select which of the many possible solutions they will use to predict on data they have never seen before.
While we know that their effectiveness relies on some form of inductive bias towards simplicity – a kind of Occam’s razor – there are many versions of the razor. The precise nature of the razor used by DNNs remained elusive.
An algorithmic information theory perspective on Occam’s razor
To unravel this mystery, our team, MPhys student Henry Rees, and DPhil students Christopher Mingard and Guillermo Valle-Pérez, turned to a branch of theoretical computer science called algorithmic information theory (AIT), based on the concept of Kolmogorov complexity, to quantify simplicity. Briefly, the Kolmogorov complexity of an object is defined as the length of the shortest programme on a universal Turing machine, a powerful computing device that can describe the object. This concept provides a fundamental way to think about randomness and structure. It is closely linked to theories of compression. A random string will have high Kolmogorov complexity K, as it's difficult to compress and requires a program about as long as the string itself to generate it (for example, Print ‘string’). Conversely, structured data will have lower complexity because it can be generated by a shorter program that captures the underlying patterns.
A fundamental result in AIT is that for sequences of fixed length, the number of sequences with Kolmogorov complexity K scales exponentially with K. This implies that most sequences will have complexity close to the maximum, while simple sequences are exceedingly rare. For instance, there are 2N binary strings of length N, and AIT predicts that the number of sequences with complexity K scales as 2K. Consequently, half of all sequences can be compressed by at most one bit, three-quarters by at most two bits, and so on, leaving the vast majority nearly incompressible and highly complex.
This principle extends to functions compatible with training data: most of these functions will also be highly complex. For this reason the rule of thumb, illustrated in Figure 1, is to avoid models with significantly more parameters than data points. Otherwise, such models are much more likely to select from the overwhelming majority of complex functions that generalise poorly than to find one of the rare simple ones that generalise well. To overcome this entropic challenge, a DNN must possess a strong inductive bias against functions with high Kolmogorov complexity.
Occam’s razor: a Bayesian perspective
To untangle the inductive bias of DNNs, the authors conducted a Bayesian analysis on the problem of learning Boolean functions – fundamental constructs in computer science that give true/false answers on data. They discovered that, although DNNs can theoretically fit any Boolean function to data, their priors exhibit a strong exponential preference for highly compressible Boolean functions over complex ones. What is remarkable is that this bias precisely counteracts the exponential growth in the number of Boolean functions with complexity.
This ‘exponential Occam’s razor’ enables DNNs to perform well on data generated by the simple Boolean functions they are biased toward. By contrast, they perform poorly on the vast majority of Boolean functions which are complex. In fact, on average over all possible Boolean functions, DNNs do no better than random guessing would.
Real-world data, however, is often highly structured and therefore relatively simple. This inbuilt bias toward simplicity helps explain how DNNs avoid the classical overfitting problems described by statistical learning theory, but only on certain types of data.
To delve deeper into the nature of this razor, we leveraged a transition to chaos, possible with certain activation functions, to artificially alter the inductive bias of DNNs. Even though these altered DNNs retain a strong bias toward simplicity, slight deviations from the specific exponential simplicity bias severely impairs their ability to generalise effectively on simple Boolean functions. This effect was observed across other learning tasks as well, highlighting that having the correct form of Occam’s razor is crucial for successful learning.
This analysis helps open the black box by shedding light on the fundamental question of how DNNs achieve the flexibility of complex algorithms while avoiding the classic problem of overfitting.
However, while these insights hold for DNNs as a whole, they are too broad to fully explain why certain DNN architectures outperform others on specific data, a question of great interest to practitioners. This suggests we need to look beyond simplicity to identify additional inductive biases driving these performance differences. An interesting link to physics is that many of these biases may be induced by ensuring that the DNNs reflect symmetries inherent in the data. For example, such principles are already exploited in convolutional neural networks (CNNs) where translational invariance helps them perform well on image data.
Future directions: a window into the natural world
Perhaps the most intriguing aspect of this study is its suggestion of a parallel between artificial intelligence and fundamental natural principles. For example, a colleague recently demonstrated to me how a CNN, trained on fluid dynamics data, could dramatically accelerate complex flow simulations. Despite being clearly overparameterised – capable of generating countless solutions consistent with the training data but not necessarily with the Navier-Stokes equations – the CNN performed remarkably well. Why? Examples like this abound. The success of DNNs at solving a broad range of scientific problems suggests something profound: that the exponential inductive bias we discovered must mirror something deep about the structure of the natural world.
Interestingly, the bias we observe in DNNs has the same functional form as the simplicity bias in evolutionary systems that we recently used to explain, for example, the prevalence of symmetry in protein complexes. This points to intriguing connections between learning and evolution, an avenue ripe for further exploration.
Deep neural networks have an inbuilt Occam's razor, C Mingard et al, Nature Communications, 14 January 2025